CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
Tianfang Zhang,
Lei Li, Yang Zhou, Wentao Liu, Chen Qian, and Xiangyang Ji
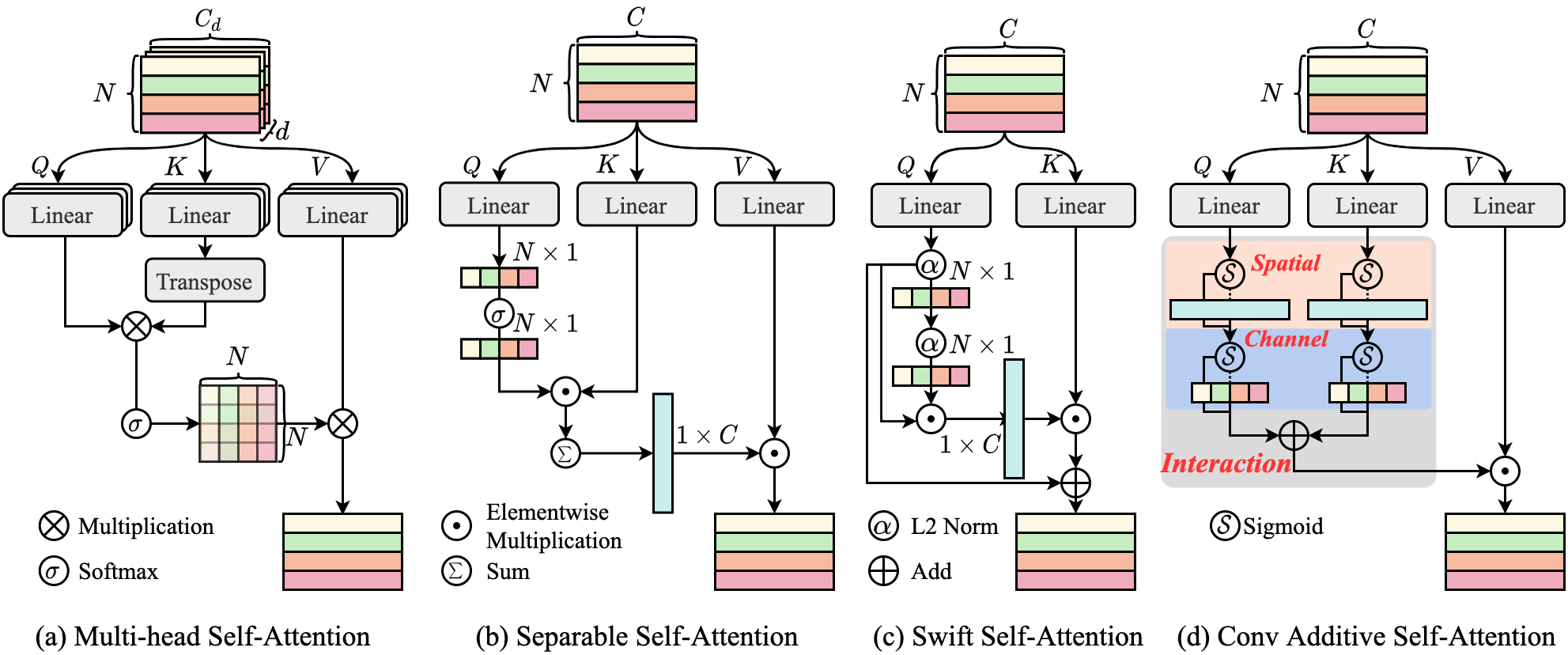
Vision Transformers (ViTs) mark a revolutionary advance in neural networks with their token mixer’s powerful global context capability. However, the pairwise token affinity and complex matrix operations limit its deployment on resource-constrained scenarios and real-time applications, such as mobile devices, although considerable efforts have been made in previous works. In this paper, we introduce CAS-ViT: Convolutional Additive Self-attention Vision Transformers, to achieve a balance between efficiency and performance in mobile applications. Firstly, we argue that the capability of token mixers to obtain global contextual information hinges on multiple information interactions, such as spatial and channel domains. Subsequently, we construct a novel additive similarity function following this paradigm and present an efficient implementation named Convolutional Additive Token Mixer (CATM). This simplification leads to a significant reduction in computational overhead. We evaluate CAS-ViT across a variety of vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our experiments, conducted on GPUs, ONNX, and iPhones, demonstrate that CAS-ViT achieves a competitive performance when compared to other state-of-the-art backbones, establishing it as a viable option for efficient mobile vision applications.