Publications
Authors marked by * contributed equally.
2025
- RPCANet++: Deep interpretable robust PCA for sparse object segmentation2025
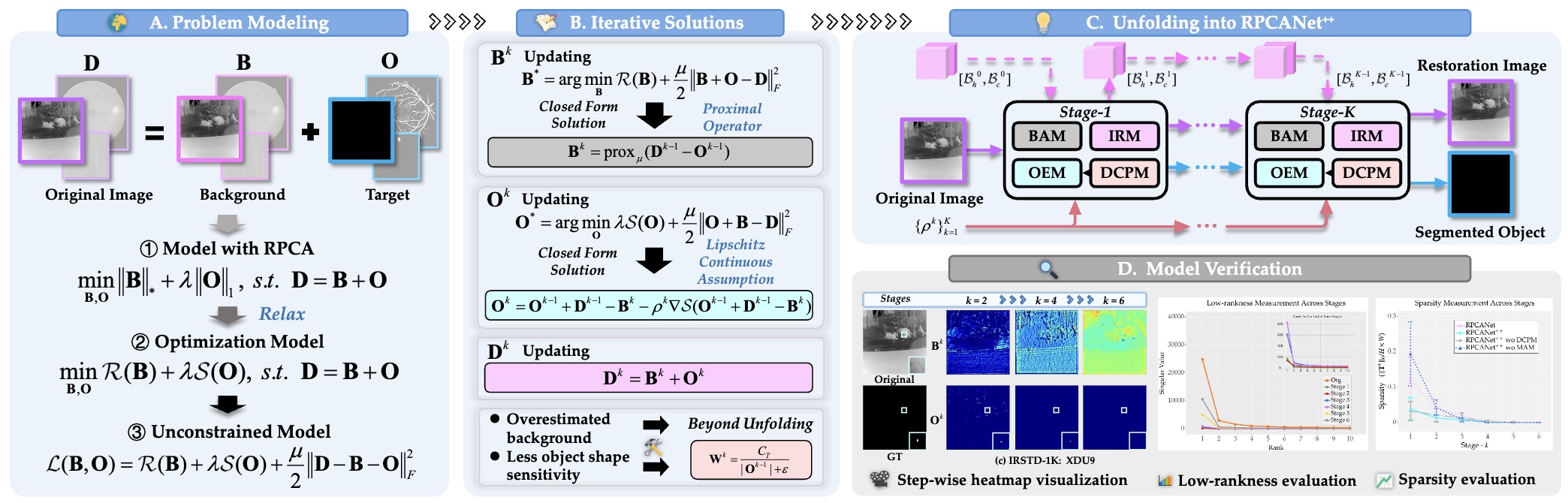
Robust principal component analysis (RPCA) decomposes an observation matrix into low-rank background and sparse object components. This capability has enabled its application in tasks ranging from image restoration to segmentation. However, traditional RPCA models suffer from computational burdens caused by matrix operations, reliance on finely tuned hyperparameters, and rigid priors that limit adaptability in dynamic scenarios. To solve these limitations, we propose RPCANet++, a sparse object segmentation framework that fuses the interpretability of RPCA with efficient deep architectures. Our approach unfolds a relaxed RPCA model into a structured network comprising a Background Approximation Module (BAM), an Object Extraction Module (OEM), and an Image Restoration Module (IRM). To mitigate inter-stage transmission loss in the BAM, we introduce a Memory-Augmented Module (MAM) to enhance background feature preservation, while a Deep Contrast Prior Module (DCPM) leverages saliency cues to expedite object extraction. Extensive experiments on diverse datasets demonstrate that RPCANet++ achieves state-of-the-art performance under various imaging scenarios. We further improve interpretability via visual and numerical low-rankness and sparsity measurements. By combining the theoretical strengths of RPCA with the efficiency of deep networks, our approach sets a new baseline for reliable and interpretable sparse object segmentation.
- Saliency at the helm: Steering infrared small target detection with learnable kernelsFengyi Wu, Anran Liu, Tianfang Zhang, and 3 more authors2025
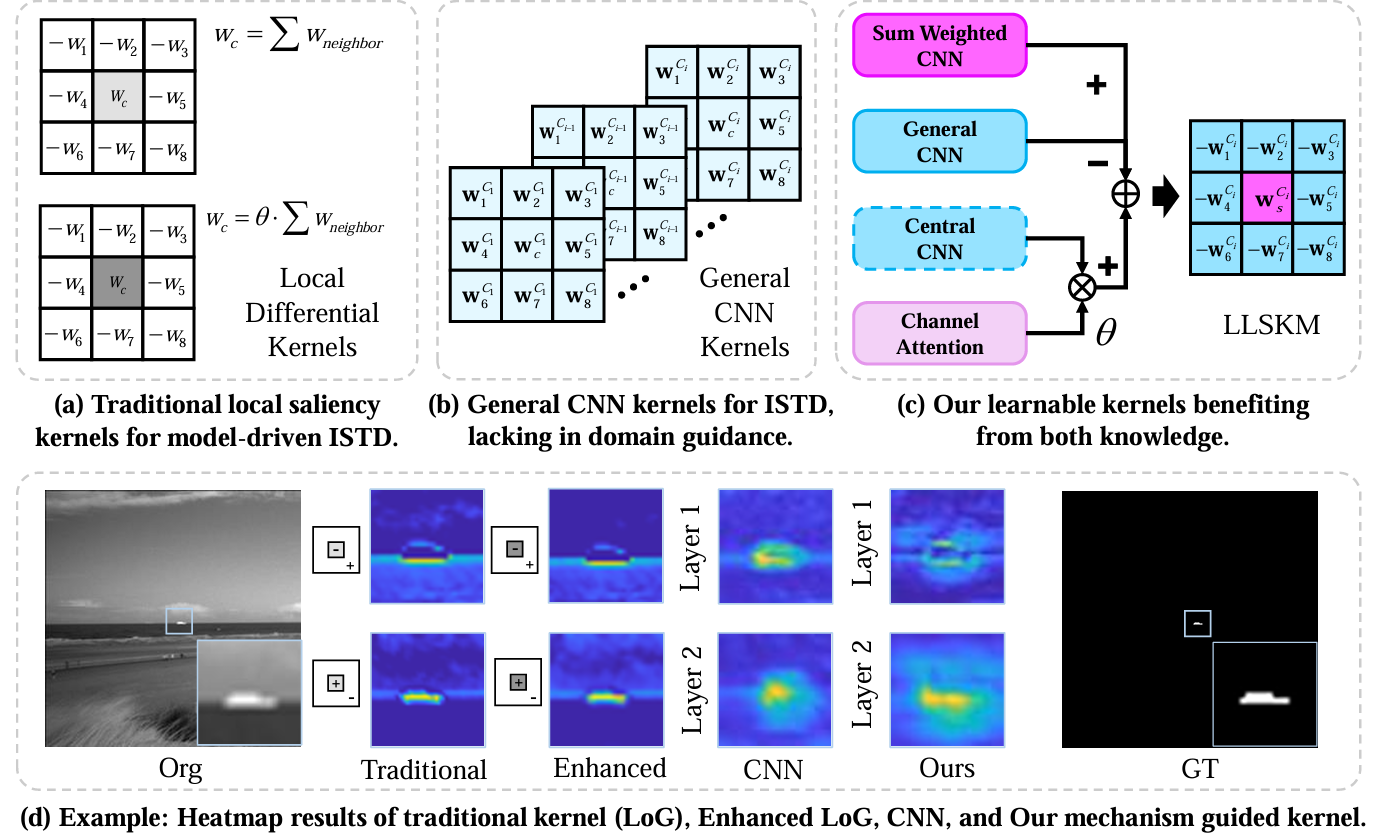
Infrared small target detection (ISTD) boasts extensive applications across civil and military domains, owing to its exceptional all-day performance. Neural network innovations have led to deep ISTD models that achieve heightened accuracy through extensive datasets. However, these general networks often fail to perceive the sensitivity of small targets and adopt heavy constructions to preserve potential target features, neglecting domain-specific insights and suffering from poor explainability. Our work seeks to rectify this by revisiting the saliency principles inherent to ISTD and developing a learnable local saliency kernel network (L2SKNet). This approach implements a learnable local saliency kernel module (LLSKM) that embodies the concept of “Center subtracts Neighbors,” guiding the network to capture the saliency features (points or edges). We enhance LLSKM by incorporating strategic dilation and structuring it hierarchically, which boosts its capability to capture multiscale infrared features while avoiding parameter explosion. In pursuit of efficiency, we also refine LLSKM into a more compact form by factorizing it into two orthogonal 1-D kernels, yielding a lightweight version. Heatmap visualizations and rigorous quantitative analyses corroborate the effectiveness of our local saliency-guided networks. Comprehensive testing reveals that L2SKNet variants outperform established baselines, demonstrating significant improvements in both visual and numerical assessments.
- The role of deductive and inductive reasoning in large language modelsChengkun Cai, Xu Zhao, Haoliang Liu, and 5 more authorsIn , 2025
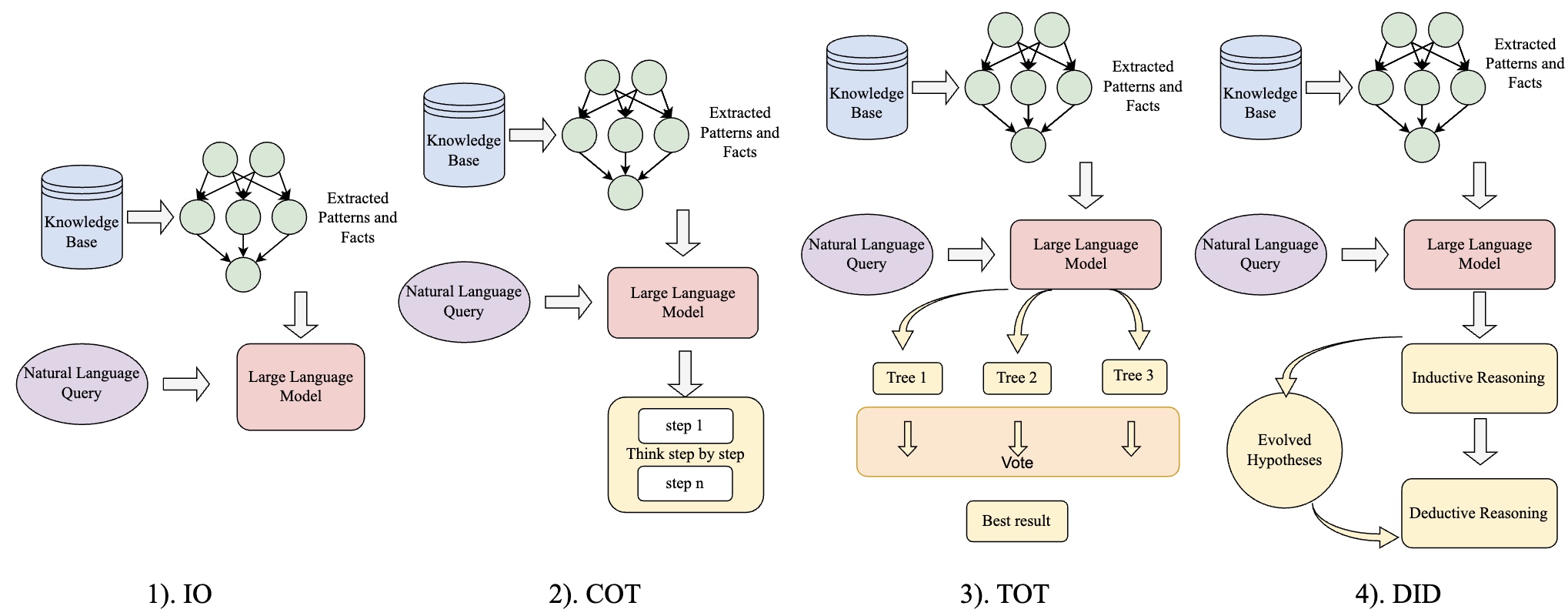
Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning tasks, yet their reliance on static prompt structures and limited adaptability to complex scenarios remains a significant challenge. In this paper, we propose the Deductive and InDuctive(DID) method, a novel framework that enhances LLM reasoning by dynamically integrating both deductive and inductive reasoning approaches. Drawing from cognitive science principles, DID implements a dual-metric complexity evaluation system that combines Littlestone dimension and information entropy to precisely assess task difficulty and guide decomposition strategies. DID enables the model to progressively adapt its reasoning pathways based on problem complexity, mirroring human cognitive processes. We evaluate DID’s effectiveness across multiple benchmarks, including the AIW and MR-GSM8K, as well as our custom Holiday Puzzle dataset for temporal reasoning. Our results demonstrate significant improvements in reasoning quality and solution accuracy - achieving 70.3% accuracy on AIW (compared to 62.2% for Tree of Thought) while maintaining lower computational costs. The success of DID in improving LLM performance while preserving computational efficiency suggests promising directions for developing more cognitively aligned and capable language models. Our work contributes a theoretically grounded, input-centric approach to enhancing LLM reasoning capabilities, offering an efficient alternative to traditional output-exploration methods.
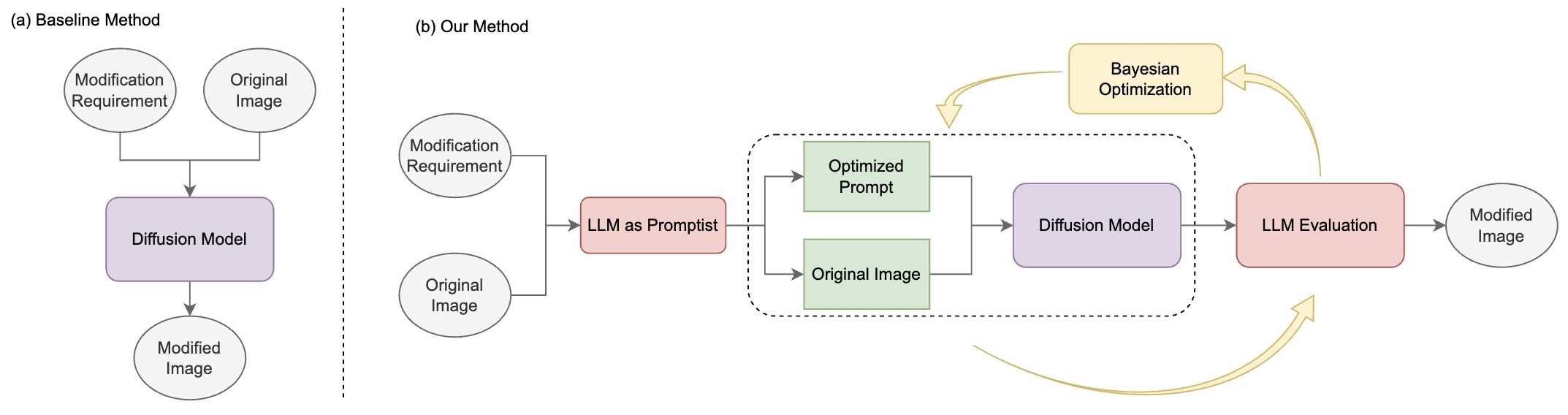
- Bayesian optimization for controlled image editing via llmsChengkun Cai, Haoliang Liu, Xu Zhao, and 6 more authorsIn , 2025
In the rapidly evolving field of image generation, achieving precise control over generated content and maintaining semantic consistency remain significant limitations, particularly concerning grounding techniques and the necessity for model fine-tuning. To address these challenges, we propose BayesGenie, an off-the-shelf approach that integrates Large Language Models (LLMs) with Bayesian Optimization to facilitate precise and user-friendly image editing. Our method enables users to modify images through natural language descriptions without manual area marking, while preserving the original image’s semantic integrity. Unlike existing techniques that require extensive pre-training or fine-tuning, our approach demonstrates remarkable adaptability across various LLMs through its model-agnostic design. BayesGenie employs an adapted Bayesian optimization strategy to automatically refine the inference process parameters, achieving high-precision image editing with minimal user intervention. Through extensive experiments across diverse scenarios, we demonstrate that our framework significantly outperforms existing methods in both editing accuracy and semantic preservation, as validated using different LLMs including Claude3 and GPT-4.
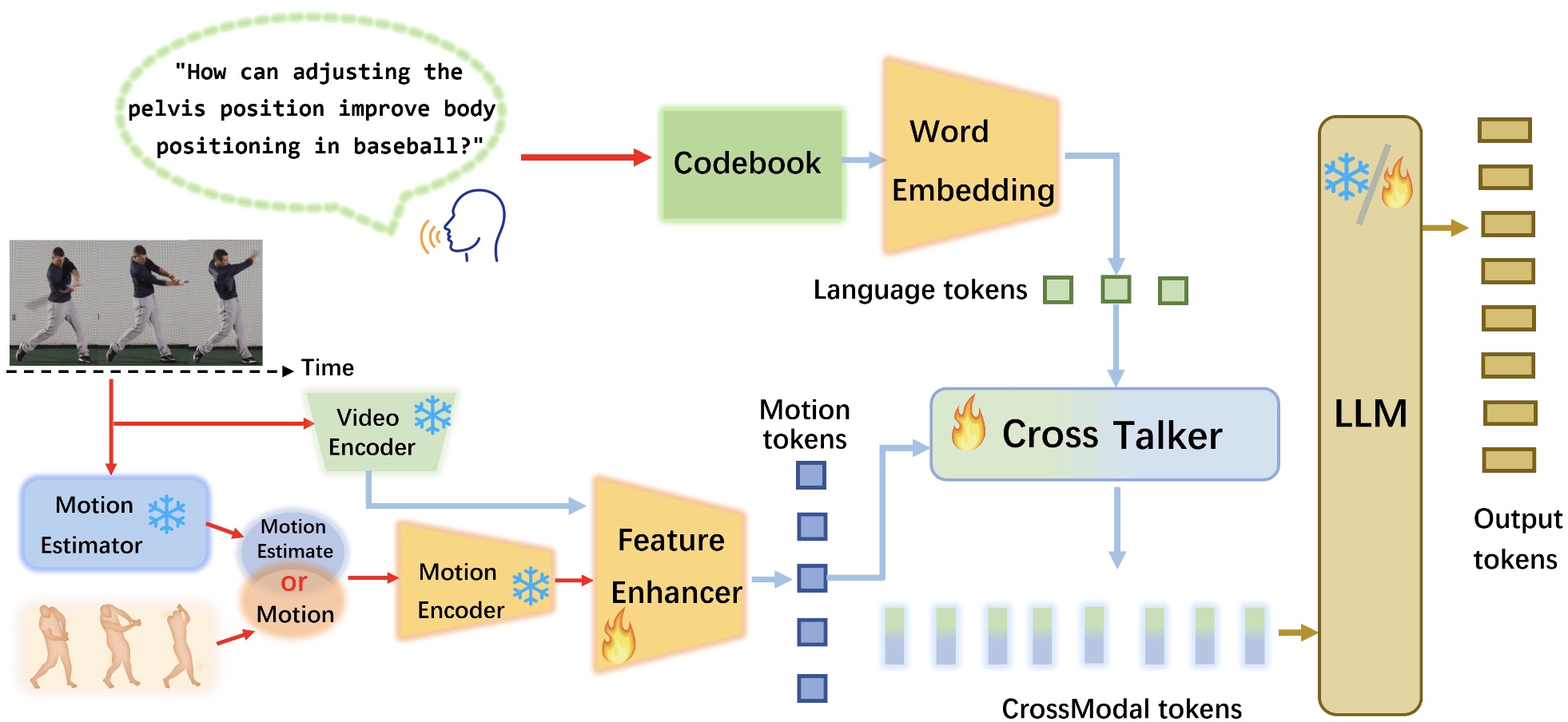
- Human motion instruction tuningLei Li, Sen Jia, Jianhao Wang, and 6 more authorsIn , 2025
This paper presents LLaMo (Large Language and Human Motion Assistant), a multimodal framework for human motion instruction tuning. In contrast to conventional instruction-tuning approaches that convert non-linguistic inputs, such as video or motion sequences, into language tokens, LLaMo retains motion in its native form for instruction tuning. This method preserves motion-specific details that are often diminished in tokenization, thereby improving the model’s ability to interpret complex human behaviors. By processing both video and motion data alongside textual inputs, LLaMo enables a flexible, human-centric analysis. Experimental evaluations across high-complexity domains, including human behaviors and professional activities, indicate that LLaMo effectively captures domain-specific knowledge, enhancing comprehension and prediction in motion-intensive scenarios. We hope LLaMo offers a foundation for future multimodal AI systems with broad applications, from sports analytics to behavioral prediction.
2024
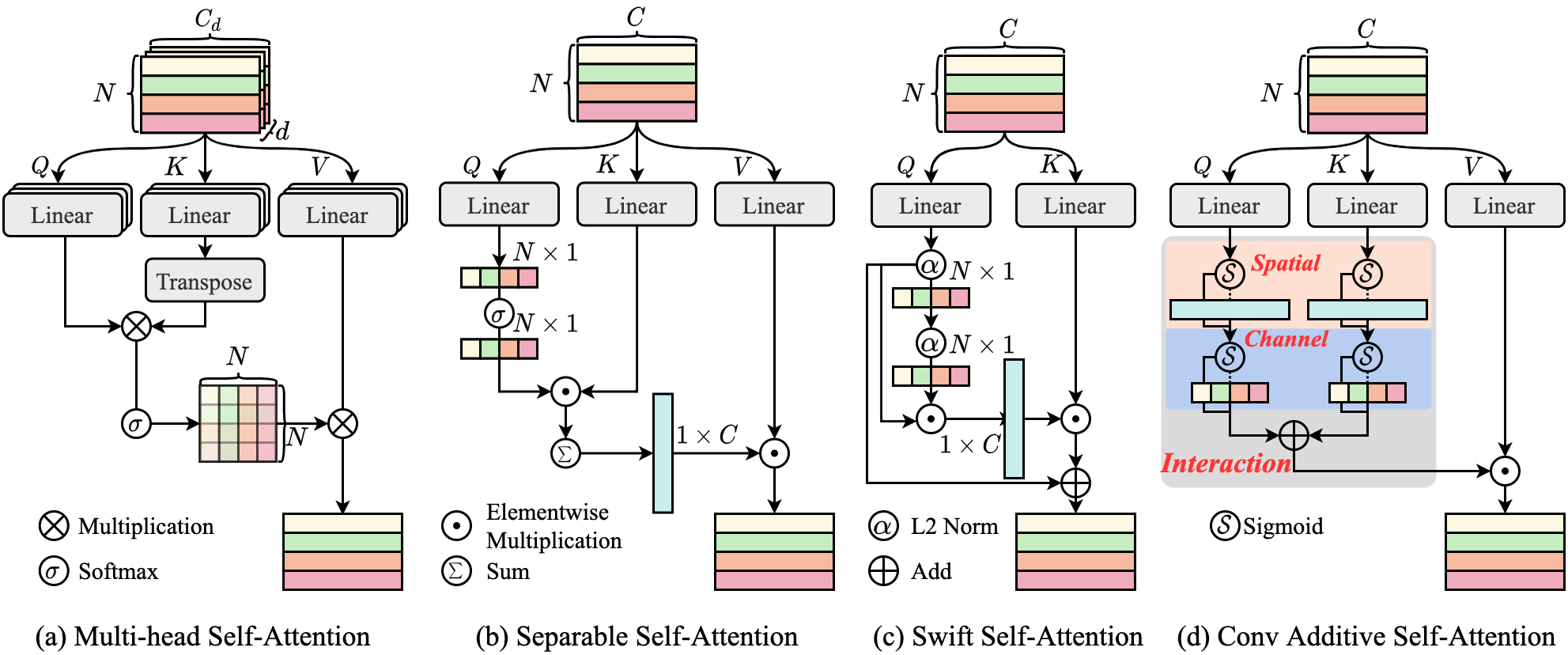
- CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile ApplicationsTianfang Zhang, Lei Li, Yang Zhou, and 3 more authors2024
Vision Transformers (ViTs) mark a revolutionary advance in neural networks with their token mixer’s powerful global context capability. However, the pairwise token affinity and complex matrix operations limit its deployment on resource-constrained scenarios and real-time applications, such as mobile devices, although considerable efforts have been made in previous works. In this paper, we introduce CAS-ViT: Convolutional Additive Self-attention Vision Transformers, to achieve a balance between efficiency and performance in mobile applications. Firstly, we argue that the capability of token mixers to obtain global contextual information hinges on multiple information interactions, such as spatial and channel domains. Subsequently, we construct a novel additive similarity function following this paradigm and present an efficient implementation named Convolutional Additive Token Mixer (CATM). This simplification leads to a significant reduction in computational overhead. We evaluate CAS-ViT across a variety of vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our experiments, conducted on GPUs, ONNX, and iPhones, demonstrate that CAS-ViT achieves a competitive performance when compared to other state-of-the-art backbones, establishing it as a viable option for efficient mobile vision applications.
2023
- RPCANet: Deep Unfolding RPCA Based Infrared Small Target DetectionIEEE/CVF Winter Conference on Applications of Computer Vision, 2023
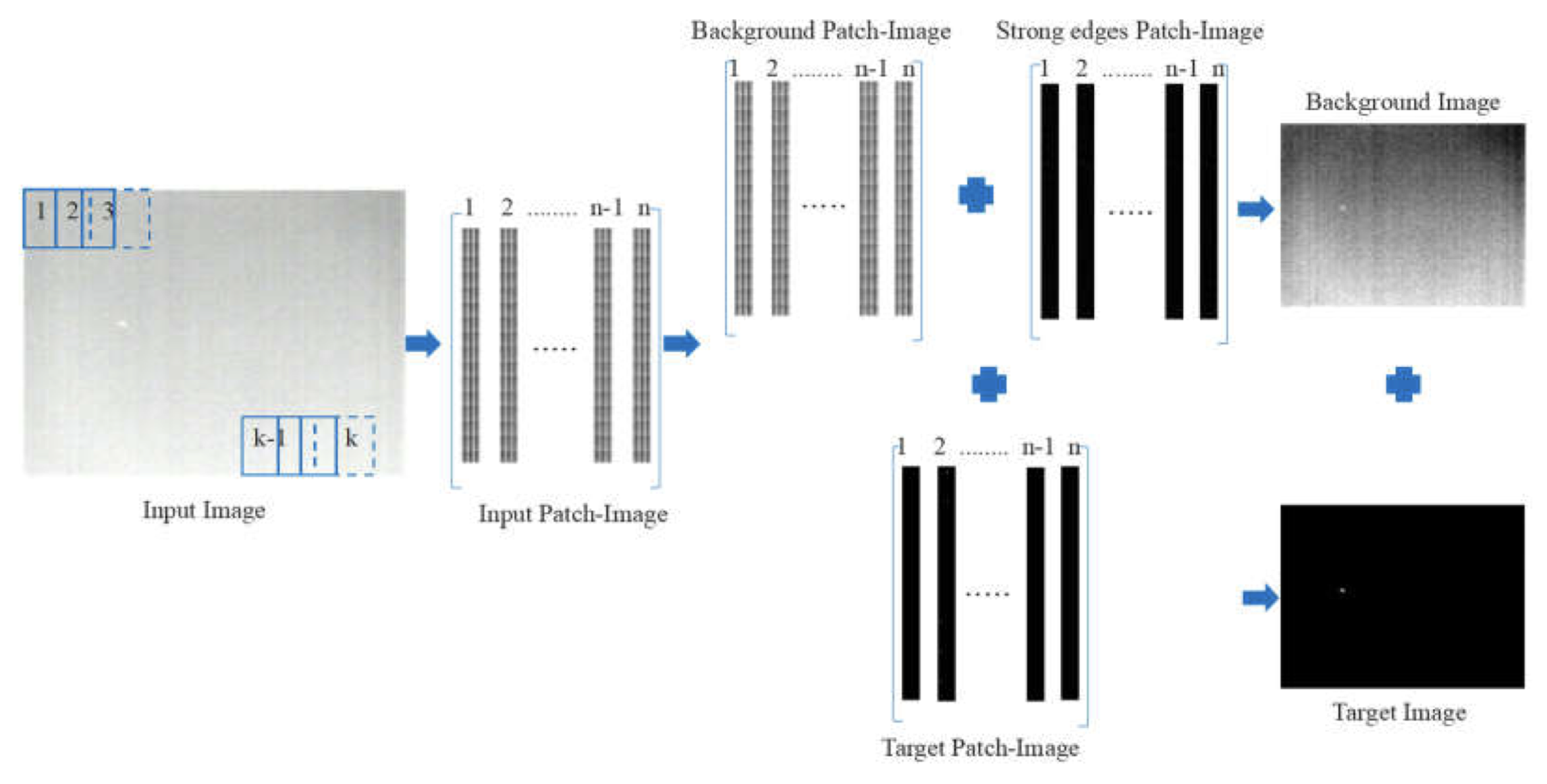
Deep learning (DL) networks have achieved remarkable performance in infrared small target detection (ISTD). However, these structures exhibit a deficiency in interpretability and are widely regarded as black boxes, as they disregard domain knowledge in ISTD. To alleviate this issue, this work proposes an interpretable deep network for detecting infrared dim targets, dubbed RPCANet. Specifically, our approach formulates the ISTD task as sparse target extraction, low-rank background estimation, and image reconstruction in a relaxed Robust Principle Component Analysis (RPCA) model. By unfolding the iterative optimization updating steps into a deep-learning framework, time-consuming and complex matrix calculations are replaced by theory-guided neural networks. RPCANet detects targets with clear interpretability and preserves the intrinsic image feature, instead of directly transforming the detection task into a matrix decomposition problem. Extensive experiments substantiate the effectiveness of our deep unfolding framework and demonstrate its trustworthy results, surpassing baseline methods in both qualitative and quantitative evaluations.
- Optimization-inspired Cumulative Transmission Network for image compressive sensingTianfang Zhang*, Lei Li*, and Zhenming PengKnowledge-Based Systems, 2023
Compressive Sensing (CS) techniques enable accurate signal reconstruction with few measurements. Deep Unfolding Networks (DUNs) have recently been shown to increase the efficiency of CS by emulating iterative CS optimization procedures by neural networks. However, most of these DUNs suffer from redundant update procedures or complex matrix operations, which can impair their reconstruction performances. Here we propose the optimization-inspired Cumulative Transmission Network (CT-Net), a DUN approach for natural image CS. We formulate an optimization procedure introducing an auxiliary variable similar to Half Quadratic Splitting (HQS). Unfolding this procedure defines the basic structure of our neural architecture, which is then further refined. A CT-Net is composed of Reconstruction Fidelity Modules (RFMs) for minimizing the reconstruction error and Constraint Gradient Approximation (CGA) modules for approximating (the gradient of) sparsity constraints instead of relying on an analytic solutions such as soft-thresholding. Furthermore, a lightweight Cumulative Transmission (CT) between CGAs in each reconstruction stage is proposed to facilitate a better feature representation. Experiments on several widely used natural image benchmarks illustrate the effectiveness of CT-Net with significant performance improvements and fewer network parameters compared to existing state-of-the-art methods. The experiments also demonstrate the scene and noise robustness of the proposed method.
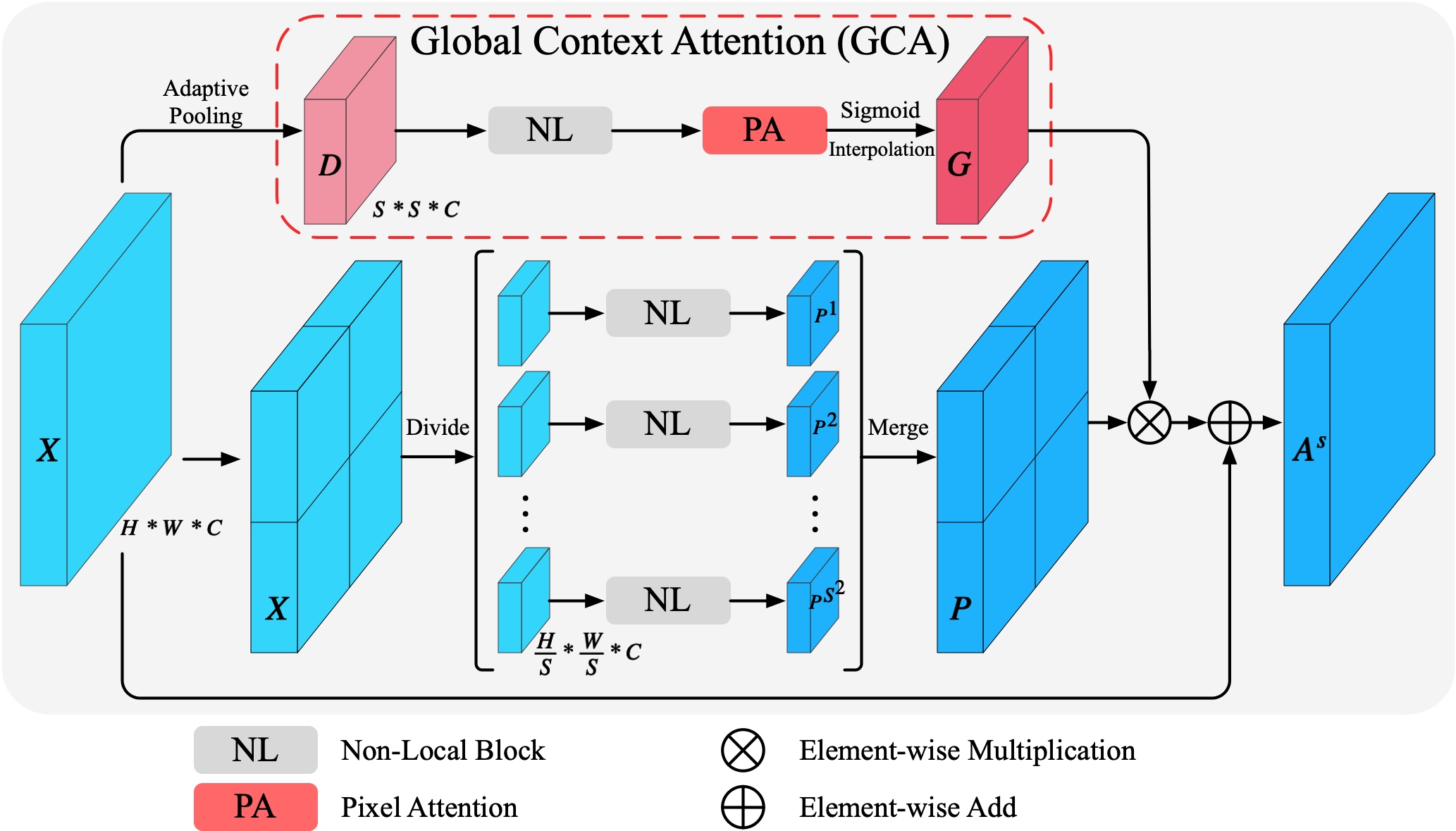
- Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex BackgroundTianfang Zhang, Lei Li, Siying Cao, and 2 more authorsIEEE Transactions on Aerospace and Electronic Systems, 2023
Infrared small target detection techniques remain a challenging task due to the complex background. To overcome this problem, by exploring context information, this research presents a data-driven approach called Attention-Guided Pyramid Context Network (AGPCNet). Specifically, we design Attention-Guided Context Block (AGCB) and perceive pixel correlations within and between patches at specific scales via Local Semantic Association (LSA) and Global Context Attention (GCA) respectively. Then the contextual information from multiple scales is fused by Context Pyramid Module (CPM) to achieve better feature representation. In the upsampling stage, we fuse the low and deep semantics through Asymmetric Fusion Module (AFM) to retain more information about small targets. The experimental results illustrate that AGPCNet has achieved state-of-the-art performance on three available infrared small target datasets.
- Computers & Graphics
 Mask-FPAN: Semi-supervised Face Parsing in the Wild with De-occlusion and UV GANComputers & Graphics, 2023
Mask-FPAN: Semi-supervised Face Parsing in the Wild with De-occlusion and UV GANComputers & Graphics, 2023The field of fine-grained semantic segmentation for a person’s face and head, which includes identifying facial parts and head components, has made significant progress in recent years. However, this task remains challenging due to the difficulty of considering ambiguous occlusions and large pose variations. To address these difficulties, we propose a new framework called Mask-FPAN. Our framework includes a de-occlusion module that learns to parse occluded faces in a semi-supervised manner, taking into account face landmark localization, face occlusion estimations, and detected head poses. Additionally, we improve the robustness of 2D face parsing by combining a 3D morphable face model with the UV GAN. We also introduce two new datasets, named FaceOccMask-HQ and CelebAMaskOcc-HQ, to aid in face parsing work. Our proposed Mask-FPAN framework successfully addresses the challenge of face parsing in the wild and achieves significant performance improvements, with a mIoU increase from 0.7353 to 0.9013 compared to the current state-of-the-art on challenging face datasets.
- NMI
 BuildSeg BuildSeg: A General Framework for the Segmentation of BuildingsLei Li, Tianfang Zhang, Stefan Oehmcke, and 2 more authorsNordic Machine Intelligence, 2023
BuildSeg BuildSeg: A General Framework for the Segmentation of BuildingsLei Li, Tianfang Zhang, Stefan Oehmcke, and 2 more authorsNordic Machine Intelligence, 2023Building segmentation from aerial images and 3D laser scanning (LiDAR) is a challenging task due to the diversity of backgrounds, building textures, and image quality. While current research using different types of convolutional and transformer networks has considerably improved the performance on this task, more precise and accurate segmentation methods for buildings are desirable for applications such as automatic mapping. In this study, we propose a general framework termed BuildSeg employing a generic approach that can be quickly applied to segment buildings. Different data sources were combined to increase generalization performance. The approach yields good results for different data sources as shown by experiments on high-resolution multi-spectral and LiDAR imagery of cities in Norway, Denmark, and France. We applied ConvNeXt and SegFormer-based models on the high-resolution aerial image dataset from the MapAI-competition. The methods achieved an IoU of 0.7902 and a boundary IoU of 0.6185 on the test set. We used post-processing to account for the rectangular shape of the objects.This increased the boundary IOU from 0.6185 to 0.6189.


2022
- LR-CSNet: Low-rank Deep Unfolding Network for Image Compressive SensingIn Proceedings of the 8th IEEE International Conference on Computer and Communications, 2022
Best paper award, Oral
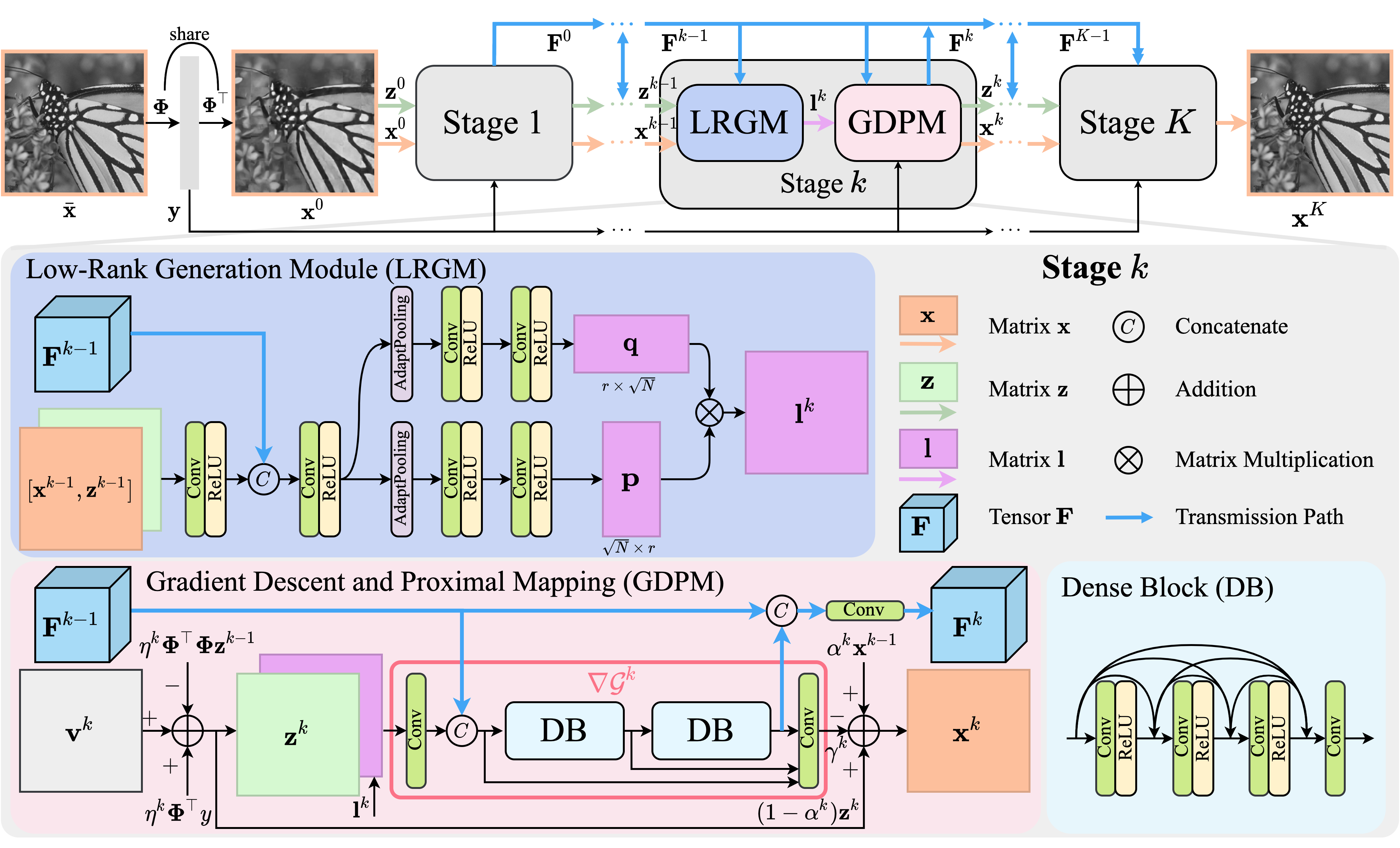
Deep unfolding networks (DUNs) have proven to be a viable approach to compressive sensing (CS). In this work, we propose a DUN called low-rank CS network (LR-CSNet) for natural image CS. Real-world image patches are often well-represented by low-rank approximations. LR-CSNet exploits this property by adding a low-rank prior to the CS optimization task. We derive a corresponding iterative optimization procedure using variable splitting, which is then translated to a new DUN architecture. The architecture uses low-rank generation modules (LRGMs), which learn low-rank matrix factorizations, as well as gradient descent and proximal mappings (GDPMs), which are proposed to extract high-frequency features to refine image details. In addition, the deep features generated at each reconstruction stage in the DUN are transferred between stages to boost the performance. Our extensive experiments on three widely considered datasets demonstrate the promising performance of LR-CSNet compared to state-of-the-art methods in natural image CS.
2021
- Infrared small target detection via self-regularized weighted sparse modelTianfang Zhang, Zhenming Peng, Hao Wu, and 3 more authorsNeurocomputing, 2021
Infrared search and track (IRST) system is widely used in many fields, however, it’s still a challenging task to detect infrared small targets in complex background. This paper proposed a novel detection method called self-regularized weighted sparse (SRWS) model. The algorithm is designed for the hypothesis that data may come from multi-subspaces. And the overlapping edge information (OEI), which can detect the background structure information, is applied to constrain the sparse item and enhance the accuracy. Furthermore, the self-regularization item is applied to mine the potential information in background, and extract clutter from multi-subspaces. Therefore, the infrared small target detection problem is transformed into an optimization problem. By combining the optimization function with alternating direction method of multipliers (ADMM), we explained the solution method of SRWS and optimized its iterative convergence condition. A series of experimental results show that the proposed method outperforms state-of-the-art baselines.

2019
- Infrared small target detection based on non-convex optimization with Lp-norm constraintTianfang Zhang, Hao Wu, Yuhan Liu, and 3 more authorsRemote Sensing, 2019
The infrared search and track (IRST) system has been widely used, and the field of infrared small target detection has also received much attention. Based on this background, this paper proposes a novel infrared small target detection method based on non-convex optimization with Lp-norm constraint (NOLC). The NOLC method strengthens the sparse item constraint with Lp-norm while appropriately scaling the constraints on low-rank item, so the NP-hard problem is transformed into a non-convex optimization problem. First, the infrared image is converted into a patch image and is secondly solved by the alternating direction method of multipliers (ADMM). In this paper, an efficient solver is given by improving the convergence strategy. The experiment shows that NOLC can accurately detect the target and greatly suppress the background, and the advantages of the NOLC method in detection efficiency and computational efficiency are verified.
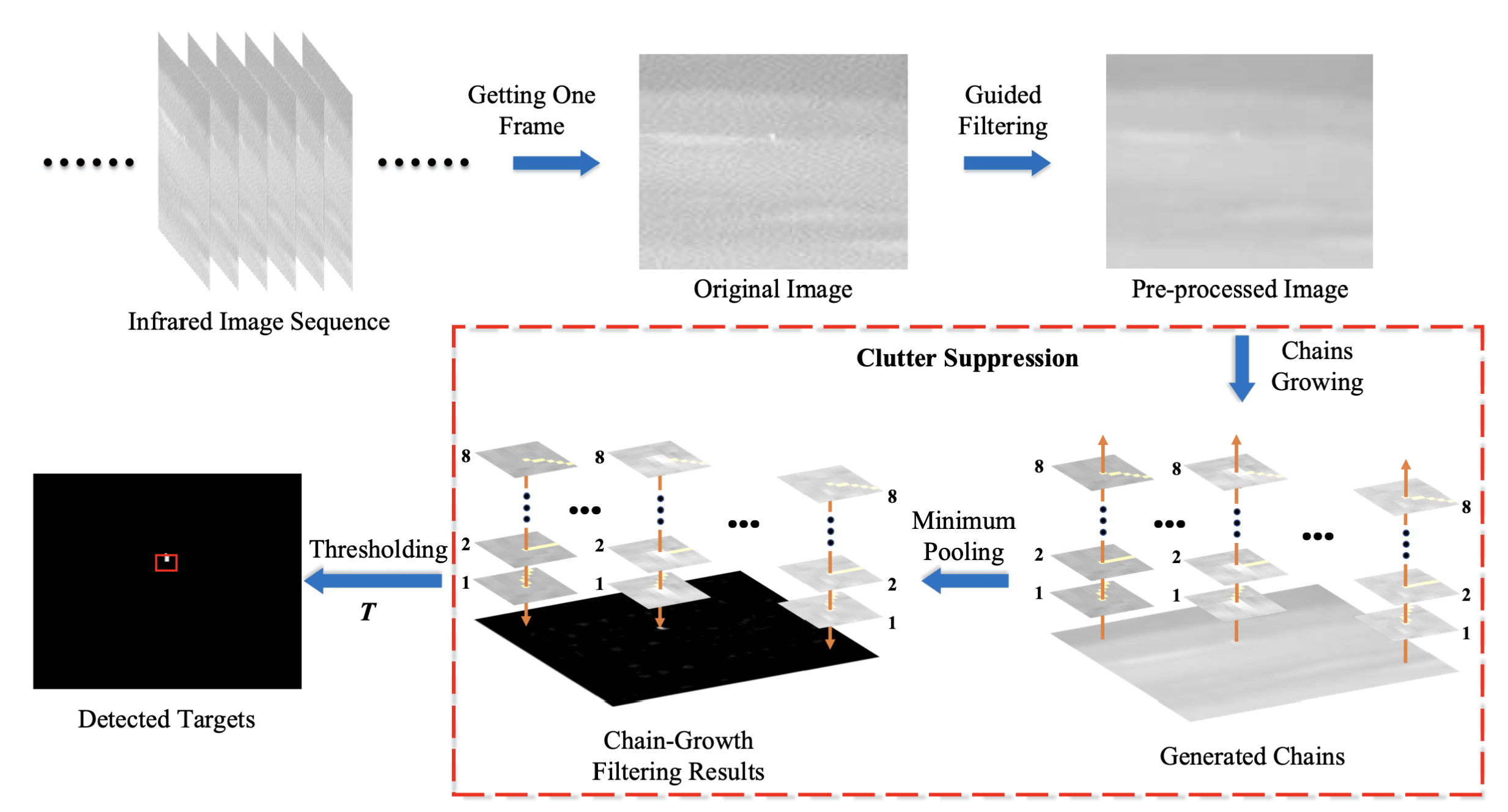
- Structure-adaptive clutter suppression for infrared small target detection: Chain-growth filteringSuqi Huang, Yuhan Liu, Yanmin He, and 2 more authorsRemote Sensing, 2019
Robust detection of infrared small target is an important and challenging task in many photoelectric detection systems. Using the difference of a specific feature between the target and the background, various detection methods were proposed in recent decades. However, most methods extract the feature in a region with fixed shape, especially in a rectangular region, which causes a problem: when faced with complex-shape clutters, the rectangular region involves the pixels inside and outside the clutters, and the significant grey-level difference among these pixels leads to a relatively large feature in the clutter area, interfering with the target detection. In this paper, we propose a structure-adaptive clutter suppression method, called chain-growth filtering, for robust infrared small target detection. The well-designed filtering model can adjust its shape to fit various clutter structures such as lines, curves and irregular edges, and thus has a more robust clutter suppression capability than the fixed-shape feature extraction strategy. In addition, the proposed method achieves a considerable anti-noise ability by employing guided filter as a preprocessing approach and enjoys the capability of multi-scale target detection without complex parameter tuning. In the experiment, we evaluate the performance of the detection method through 12 typical infrared scenes which contain different types of clutters. Compared with seven state-of-the-art methods, the proposed method shows the superior clutter-suppression effects for various types of clutters and the excellent detection performance for various scenes.
- Symmetry
 Infrared dim target detection using shearlet’s kurtosis maximization under non-uniform backgroundLingbing Peng, Tianfang Zhang, Yuhan Liu, and 2 more authorsSymmetry, 2019
Infrared dim target detection using shearlet’s kurtosis maximization under non-uniform backgroundLingbing Peng, Tianfang Zhang, Yuhan Liu, and 2 more authorsSymmetry, 2019A novel method based on multiscale and multidirectional feature fusion in the shearlet transform domain and kurtosis maximization for detecting the dim target in infrared images with a low signal-to-noise ratio (SNR) and serious interference caused by a cluttered and non-uniform background is presented in this paper. First, an original image is decomposed using the shearlet transform with translation invariance. Second, various directions of high-frequency subbands are fused and the corresponding kurtosis of fused image is computed. The targets can be enhanced by strengthening the column with maximum kurtosis. Then, processed high-frequency subbands on different scales of images are merged. Finally, the dim targets are detected by an adaptive threshold with a maximum contrast criterion (MCC). The experimental results show that the proposed method has good performance for infrared target detection in comparison with the nonsubsampled contourlet transform (NSCT) method.
- Opt. Rev.
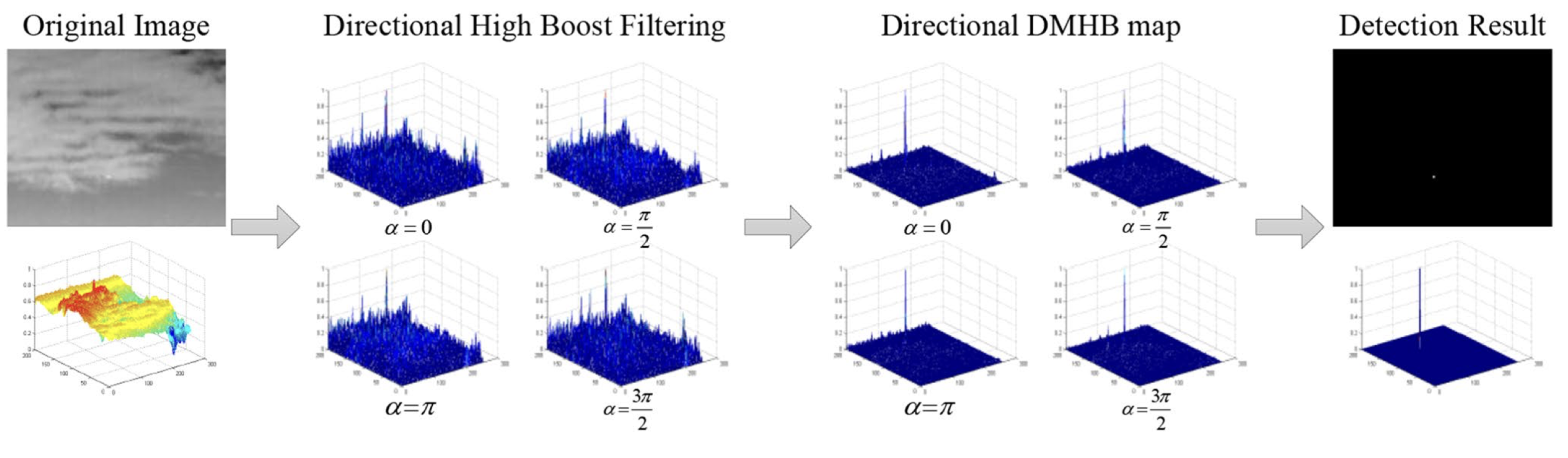 Infrared small-target detection based on multi-directional multi-scale high-boost responseLingbing Peng, Tianfang Zhang, Suqi Huang, and 5 more authorsOptical Review, 2019
Infrared small-target detection based on multi-directional multi-scale high-boost responseLingbing Peng, Tianfang Zhang, Suqi Huang, and 5 more authorsOptical Review, 2019As of late, infrared (IR) small-target detection technology is broadly utilized in low-altitude monitoring frameworks, target-tracking frameworks, precise guidance frameworks and forest fire prevention frameworks. In this paper, we propose an infrared small-target detection strategy based on multi-directional multi-scale high-boost response (MDMSHB). First, an eight-direction filtering template is proposed, which can consider the directional information of the image and significantly suppress heterogeneous background such as cloud, linear interference and interface like ocean–sky background. Then, a map based on multi-directional multi-scale high-boost response (MDMSHB map) is calculated. Finally, a straightforward threshold segmentation technique is utilized to get the detection result. The simulation results comparing this method with the four state-of-the-art strategies in six sequences demonstrate that the proposed strategy can adequately suppress heterogeneous background and arbitrary noise. The approach can improve detection rate and reduce false alert rate as well.
2018
- Infrared Small Target Detection via Non-convex Rank Approximation Minimization Joint l2,1 NormLandan Zhang, Lingbing Peng, Tianfang Zhang, and 2 more authorsRemote Sensing, 2018
To improve the detection ability of infrared small targets in complex backgrounds, a novel method based on non-convex rank approximation minimization joint l2,1 norm (NRAM) was proposed. Due to the defects of the nuclear norm and l1 norm, the state-of-the-art infrared image-patch (IPI) model usually leaves background residuals in the target image. To fix this problem, a non-convex, tighter rank surrogate and weighted l1 norm are instead utilized, which can suppress the background better while preserving the target efficiently. Considering that many state-of-the-art methods are still unable to fully suppress sparse strong edges, the structured l2,1 norm was introduced to wipe out the strong residuals. Furthermore, with the help of exploiting the structured norm and tighter rank surrogate, the proposed model was more robust when facing various complex or blurry scenes. To solve this non-convex model, an efficient optimization algorithm based on alternating direction method of multipliers (ADMM) plus difference of convex (DC) programming was designed. Extensive experimental results illustrate that the proposed method not only shows superiority in background suppression and target enhancement, but also reduces the computational complexity compared with other baselines.